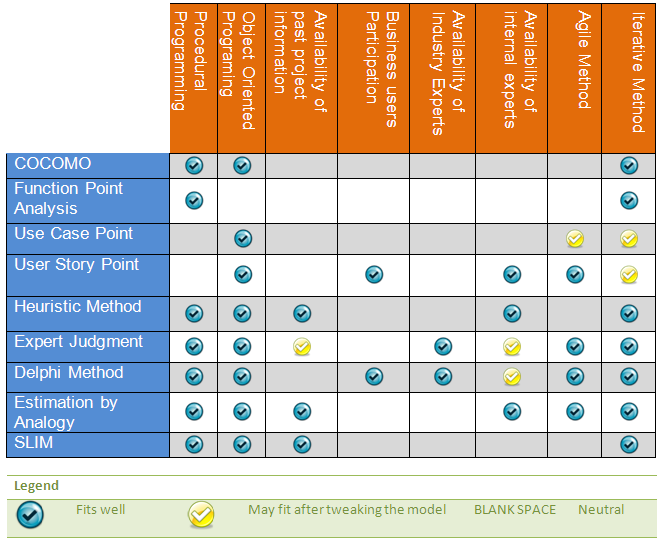
Finally
we're at the point where we now know why we develop estimation fatigue when asked to estimate a software project and also we've visited some
of the options that we have to avoid that fatigue (refer to the previous
posts: Fighting Estimation Fatigue Part 1, Part 2, Part 3 and Part 4). But If all of those seems too much for you, and if you have a project in hand, and can't wait to read through all those posts then you
can just go over this post and use it as a jump starter for your
project. The best
practices described here can be used with the use of any specific
standard software estimation model or no model at all:

- Estimate the effort in terms of scenarios i.e. Best Case and Worst Case scenario and then take the average of both to set the target date of your project (refer to PERT)
- Create the estimations in the form of range value rather than a single number estimation. After all, the estimation is an educated guess, so, you don't need to pretend that you have psychic power to reveal a golden number
- When the project has lot of uncertainty and unknowns, provide multiple estimations with different set of assumptions for each estimation
- Use a confidence level based estimation when you’re hard pressed to give a single estimation point. E.g. If you’re given no chance but told to deliver the software before the Christmas day, then the estimation could be given as – Release date on 12/25/2014 (60% confidence level)
- Ball park figure is a dangerous trap, never fall into that. If you're forced to give a ball park figure estimation, never forget to add the underlying assumptions and associated risks along with that estimation
- Trust your intuition, never fear to use Estimation by Analogy technique. Though Estimation by Analogy may seem dangerous but if the organization takes similar projects repeatedly, be bold to take that route. This is not less accurate than other standard estimation methods, nevertheless the quickest and cheapest of all
- Empirical estimation models needs time to be matured and predictable. If the software project is one time endeavor and may not be repeated, do not use empirical estimation model. The promise of improving the accuracy can’t be harvested without the repetition
- Estimation should be done at the most possible granular level (also known as Bottom up Estimation) and then roll up to the complete project level to get the project estimation. The granular level estimation offsets most of the inaccuracies in estimation
- Estimation at granular levels can be used to defend your estimation as well. Management tend to raise question to a lump sum estimation of a project but would think twice to question a granular level of each features that aggregate into the project level estimation. Moreover, when you will be asked to add a new feature in the software (and it is almost guaranteed that you would be asked for it), that granularity helps to identify feature(s) that you can trade in, otherwise you would have no choice but to swallow the change in to your project
- If you choose to use a standard software estimation model, use at least two models and compare the results. If they're close, it would give you the confidence on your estimation
- Revisit the estimation once the project is completed. This time, re-estimate the relative size of each tasks as well as the actual effort hours and record them. Once you have enough empirical data, you can use them to provide a ball park figure when asked by executive management.
It
is as important to communicate
the estimation right as the estimation process itself. Often time a
great deal of
time and money are invested for the estimation process whereas leaving
the the presentation of the estimation unfocused. It's also very
important to set the right tone that creates the environment of
acceptance. I've compiled some of the
communication best practices for software estimation that, if followed
appropriately, can increase the chance of
acceptance of your estimation:

- Don’t fall in the trap of telling what the project sponsors and executives want to hear. Because you are the one who one who would be held responsible for the estimation commitment that you made
- Document all the assumptions that were made throughout the estimation process. For example, if the estimation value is converted into time duration, make sure to document what was the competency level of programmers that was assumed to get the person day
- Educate your stakeholders about the “Cone of uncertainty” of software estimation process. The stakeholders will be more susceptible to accept the higher error margin when the estimation is made early in the project's life cycle, as shown in the "cone of uncertainty"
- Always present the estimation in terms of a range value rather than one single number. By definition, the word estimation is a rough calculation. So it wouldn’t be a wise idea to present the estimation as a single number which would mislead the audience about it's perceived accuracy
- If absolutely necessary to provide a single value estimation, use the plus-or-minus qualifier e.g. rather than telling that the software would take 6 months, express it in 6 months +- 2 months. So, the stakeholders gets what they wanted, and the estimator is covered from future accusation
- You can also use a confidence factor while presenting your estimation. As an example, It’s better to communicate that you're, for instance, 70% confident that the project would be completed in 6 months i.e. if the project is targeted to deliver after 6 months, there's a 30% chance of missing the deadline
- Don’t pretend the all sunny day scenario for your project. Though some people may consider it as pessimistic approach, but communicate the predicted implementation risks Add the perceived risks that were identified during the estimation process and use them to come up with plus-minus qualifier, range and confidence level based single estimation
- Even though it may not be asked, it's better to present more than one estimation values with different set of scopes. As for an example: if you have a system to develop that has100 use cases, you may provide two estimations: one for the entire set i.e. 100 use cases and another is for top 80% use cases. It would help you to avoid the trap of "everything is absolutely required" statement. In reality they are always not true. So if the estimation of everything seems too long to the the stakeholders, there's an alternate with reduced set of features which is analogous to the options offered by your GPS - shortest distance or shortest time; and you do the pick