We're so lucky now that we don't have to be confined within a few data management and processing solutions as more and more open source or closed source software and systems are proven to be so much dependable that you see the company like Facebook and Yahoo are using them to maintain their leading market share. I've put together a short notes on some of the popular systems.
- It supports ANSI SQL
(also dubbed as Oracle Query) and PL/SQL for procedural programming
Hadoop
Hadoop,
a software library framework, is designed to process a large volume of data
(also known as Big Data) in a distributed computing environment. Fundamentally,
Hadoop decouples the data and its processing into two paradigms: the data is
stored in a distributed file system (called as Hadoop Distributed File Systems
or HDFS) and the processing happens in an infrastructure where clusters of
commodity hardware form the distributed computing environment. Hadoop is
designed to keep the scalability of processing in mind thus it can scales from
a single machine to thousands machines. Each processing unit in the Hadoop
cluster has its local storage and computing capacity which greatly increase the
processing speed by keeping data next the processor. The risk of losing data
due to failure of the processing node in a cluster is countered by the HDFS
whereas the high availability of processing node in the cluster is controlled
in the software itself rather than adding extra stack of hardware. The other
core modules of Hadoop are the Hadoop YARN and Hadoop MapReduce. Hadoop YARN is
the framework for job scheduling and cluster resource management whereas Hadoop
MapReduce is a batch based distributed computing software framework that allows
to parallelize work over a large volume of raw data which could take days or
longer using conventional serial computing techniques, can be used reduced down
to minutes on a Hadoop cluster. It simplifies the parallel computing by abstracting
away the complexities involved in working with distributed systems, such as
computational parallelization, work distribution, and dealing with unreliable
hardware and software.
Cassandra
Apache
Cassandra is a NoSQL distributed database management systems designed to handle
large volume of data with no Single-Point-Of-Failure (SPOF). The heart of the
Cassandra is the Data Model which is fundamentally different from a Relational
Database Management Systems. In Cassandra, the data is structured in a column
family which is analogous to RDMBS Table but unlike RDBMS, it doesn’t need to
have same number and type of columns for all the rows. Each Column in a column
family has three attributes: column name, column value and timestamp. A
multi-dimension approach of designing a Cassandra data model is to use what it
called as Super Column within a Column Family. The main advantage of Cassandra
is that it can replicates data transparently in different nodes even in across
data centers and all that are achieved without compromising the highest level
of fault tolerance. As Cassandra doesn’t use Mast-Slave model to achieve the
location transparency and distributed data architecture, it’s free from any
bottleneck. To achieve that highest level distributed data availability, some
of the features of data access like joining rows weren’t included. There’s also
a tradeoff that needs to be made in the area of consistency and availability
but that are all configurable (“Tunable Consistency”, as Cassandra coined the
term).
Essbase
Essbase,
originated from Extended Spreadsheet Database, is an object oriented and
multidimensional database management systems, specially designed to provide the
OLAP (Online Analytical Processing) capabilities to users to model, analyze,
and interpret the most complex business scenarios. As an OLAP tool, Essbase
provides the slicing and dicing of data from a very large volume of data that’s
organized into a cross sectional groups of hierarchical dimensions. It is
optimized to support OLAP capabilities as opposed to OLTP (Online Transactional
Processing, like Oracle RDBMS.
SQLServer
Microsoft
SQLServer is the second popular Relational Database Management System (RDBMS)
after Oracle RDBMS. It provides all the features of a relational database like,
table, view, table joining, query processing, transactional update etc. SQL
Server supports both T-SQL (Transact SQL) and ANSI SQL as query language. One
of the drawbacks of MS SQLServer is that it can only be deployed on Microsoft
Windows Operating System environment. In addition to typical RDBMS features, it
also provides replication service, notification service, reporting service etc.
As a product from Microsoft, it strongly bonds with its programming environment
(.NET) through SQL CLR (Common Language Runtime) and easily accessible through
Microsoft Visual Studio development environment.
MySQL
MySQL
is one of most popular RDBMS which is open source in nature and managed by
Oracle. This has most of the features like other RDMBS like Oracle RDBMS and MS
SQLServer, but it’s mostly used in a smaller scale environment (with few
exceptions) and very popular among the open source community. Some of the
characteristics of MySQL are:
-
It’s
a Relational database and provides both transactional and non-transactional
storage engines
-
It
supports ANSI SQL query language and as well as procedural programming using
Stored Procedure and Functions
-
It’s
open source
-
It’s
very fast, reliable and scalable
-
It
can work in both client/server and embedded model
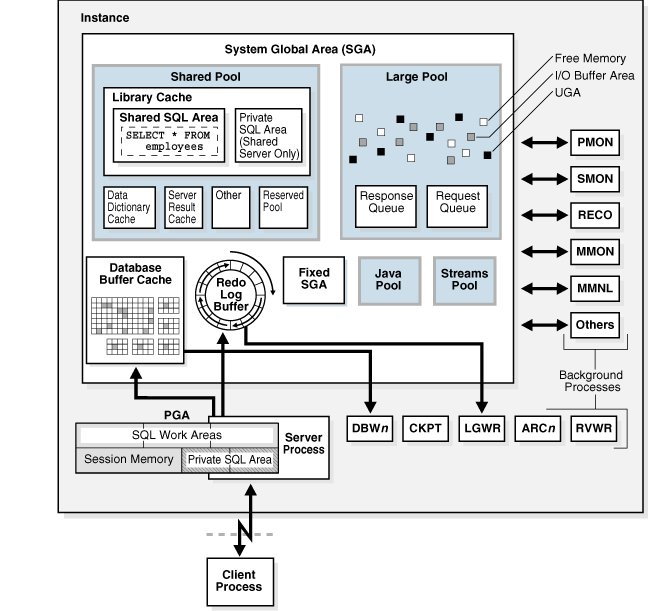
Oracle
Oracle
is an Object Relational Database Management Systems which provides an added
flavor of Object orientation in the Relational Database realm. This is the most
popular and widely used RDMBS. Internally Oracle RDBMS is divided into Oracle
Instance and Database. The Oracle instance consists of the memory on RAM and
server processes which is identified by System Identifier (SID). The database
part is consists of the data files in the Operating System. There are number of
background processes works in parallel to provide very fast access to the data
and modify the same. Oracle database comes with so many added features which
makes it the number one RDBMS, some of them are:
- provides Real Application Cluster (RAC) to enable maximum availability in
terms of Oracle instance failure
- use Automatic Storage Management (ASM) and Automatic Memory Management (AMM)
to simplify its management of data and performance
- Oracle
has proprietary backup and recovery tool (RMAN) for simplified backup and restoration of data in case of instance failure and data corruption