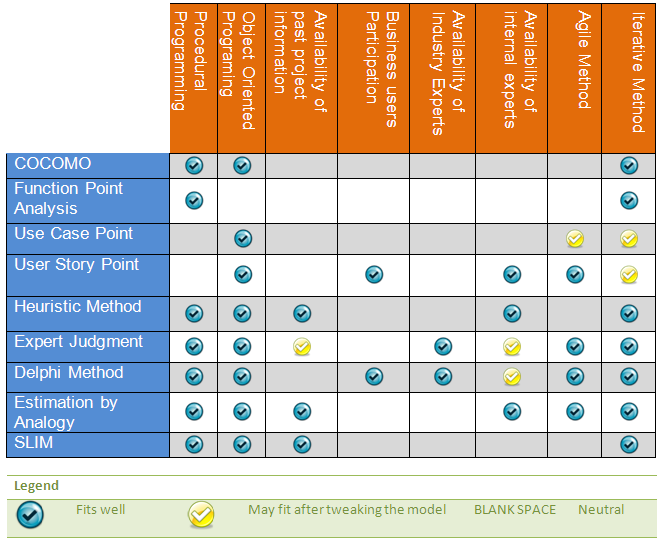
Let's first start with the basics of estimation thing and then I will touch upon some of the popular and useful estimation models. This will give a solid foundation for the upcoming posts of this Software Estimation series.
A Google
search reveals the “meaning of estimation” as “a
rough calculation of the value, number, quantity, or extent of something”. Even
though by definition “estimation” is a rough calculation but most of us when we
hear the word “estimation” in software development, we internally treat it as
“actual” and commitment. Software Estimation is often considered as a
black art which is mostly neglected during the inception of an Information
Technology Project, nonetheless, almost always is used to formulate the two
most important attributes of a project i.e. the cost and the deadline, and
often with rigid expectation of high level of accuracy.
Software
Estimation is an widely, and in some cases overly, used topic in the field of computer science and
software engineering. People were looking for a panacea where one can predict the schedule....A wide range of models have been developed since mid of
twentieth century to solve the premise of sizing the software before it is
built. Some of them are very effective at their time with a certain programing
practice whereas the usefulness of some of them transcended the boundary of
technology and programing practices. Here are some of the very popular and
widely used software cost estimation models and metrics:
Line of Code (LOC/SLOC)
Though
Line of Code or Source Line of Code (SLOC) is not a software estimation model
in itself, this is the most widely used metric in software estimation models to
determine the size e.g. COCOMO, SLIM, SEER-SEM, PRICE-S. Moreover, the most of
ad-hoc estimation models used in the software house, and they are the majority
in the software estimation landscape, uses this metric as in input to estimate
the software development effort. The popularity of the LOC is not because that
this gives an accurate picture of the size of the software but due to its simplistic
connotation to the direct result of programming work of developing a software
product. The primary advantage of SLOC is that it’s easily agreeable by the
parties that are involved in the project to consider SLOC for software sizing
as, in reality, source code is the apparent building block of the software.
Despite of its sheer popularity, the use of LOC in software estimation is the
biggest contributor to estimation inaccuracy. The reasons behind this
inaccuracy are:
- There’s
no standard or single agreed upon method on counting Source Line of Code
- SLOC
is language dependent; changing the programming language immediately impacts it
- It
is inherently inconceivable to predict SLOC from scope document with a very
high level of requirements
- There’s
a psychological toll of SLOC as it may incentivize the bad coding practice thus
increases the SLOC
COCOMO
COCOMO, stands
for COnstructive COst MOdel, is one of the early generation software cost estimation
model and enjoyed its early popularity in nineteen eighties. It uses Line of
Code as a basis of estimation and suffers all the shortcomings that I mentioned
above in SLOC. I believe COCOMO is not very effective in this software development
age where Object Oriented Programming rules the world and LOC doesn’t make a
whole lot of sense in OOP in terms of effort estimation. If you’re still
interested (after my all wrath on COCOMO), you can visit http://en.wikipedia.org/wiki/COCOMO and http://www.softstarsystems.com/overview.htm to learn more
Function Point Analysis
The obvious limitations on guessing LOC of a
to-be-built software paved the way for another popular and somewhat realistic
during early phase of a software project , which his called Function Point
Analysis (FPA). In FPA, the software size is measured through a construct
termed ‘Function Points’ (FP). Function points allow the measurement of
software size in standard units, independent of the underlying language in
which the software is developed. Instead of counting the lines of code that
make up a system, count the number of externals (inputs, outputs, inquiries,
and interfaces) that make up the system.
There are five types of externals to count:
External inputs, External outputs, External inquiries, External interfaces, and
Internal data files. The below Value Adjustment Multiplier (VAM) formula is
used to obtain the function point count:
Where Vi is a rating
of 0 to 5 for fourteen factors predefined factors.
The primary advantages of using Function Point
Analysis model is that it measures the size of the solution rather than the
problem and is extremely useful for the transaction processing systems (e.g.
MIS applications). Moreover, FPA can be derived directly from the requirements
and easily understood by the
non-technical user. However, it does not provide an accurate estimate when
dealing with command and control software, switching software, systems software
or embedded systems. Moreover, FPA isn’t very effective in Object-Oriented
software development that uses Use Cases and converting Use Cases into Function
Points may be counter intuitive.
Use Case Points Method (UUCPM)
Similar in concept to function points, the
theoretical basis of the Use Case Points Method, first described by Gustav
Karner, is based on use cases as a basic notation for representation of
functionality, and uses case points, like function points, measure the size of
the system. Once we know the approximate size of a system, we can derive an
expected duration for the project if we also know (or can estimate) the team’s
rate of progress. In this approach, the first step is to calculate a measure
called the unadjusted use case point (UUCP) count. To the UUCP count is applied
a technical adjustment factor, as per FPA, albeit the factors themselves have
been changed to reflect the different methodology that underpins development
with use case. In addition, the UUCPM also defines a set of environmental
(project) factors that contribute to a weighting factor that is also used to
modify the UUCP measure. Four important formula used in UCP are Unadjusted Use
case Points (UUCP), Technical Complexity Factor (TCF), Environment Factor (EF)
and Use Case Point (UCP):



Once the number of UCP has been determined, an
effort estimate can be calculated by multiplying the number of UCP by a fixed
number of hours.
The primary advantages of UCP model is that it
can be automated thus saving the team a great deal of estimating time. Of
course, there’s the counter argument that an estimate is only as good as the
effort put into it. Additionally, they are a very pure measure of size as it
allows separating estimating size from deriving duration. Moreover, by
establishing average implementation time per UCP, forecasting is possible for
future schedules. In the contrary, the fundamental problem with UCP is that the
estimate cannot be arrived at until all of the use cases are written. While use
case points may work well for creating a rough, initial estimate of overall
project size, they are much less useful in driving the iteration-to-iteration
work of a team. A related issue is that the rules for determining what
constitutes a transaction are imprecise and since the detail in a use case varies
tremendously by the author of the use case, the approach is flawed. Moreover,
few Technical Factors do not really have an impact across the overall project,
yet, the way they are multiplied with the weight do impact the overall size.
The installation ease factor is an example of such. Finally, like most other
estimation models, they do not fit into the agile development methodology.
User Story Points (USP)
User stories, which help shifting the focus
from writing about requirements to talking about them, are the foundational
block of Agile development technique. All Agile user stories include a written
sentence or two, and more importantly a series of conversations about the
desired functionality from the perspective of the user of the system. In Agile
world, the method of estimating the size of the software is the User story
points which are a unit of measure for expressing the overall size of a user
story, feature, or other piece of work.
It tells us how big a story is, relative to others, either in terms of
size or complexity by using relative sizing technique. Popular sizing
techniques include- Fibonacci series (1, 2, 3, 5, 8, 13, 21, etc.) and T-shirt
size (S, M, L, XL, XXL, etc.). Then estimate the size of each user stories with
the entire team, usually through planning poker session.
The major advantage of User Story Point is
that it is relatively easy and fun to estimate the relative size of a user
story. Also the estimated size of the product is the outcome of a consensus of
the team, so the ownership is, which has psychological influence to achieve higher
throughput. On the contrary, benchmarking of size is challenging as the story
points taken by one team cannot be compared with another team’s USP. Also some
people may find it hard to get to the duration form the USP as there’s
practically no direct relationship between user story point and person hour. If
the team is not diverse enough to balance out the skewed sizing due to the
biasness of a particular group, the sizing, eventually, could be proved to be
useless. A subtle risk exists of inflated sizing by the development team if
management has unrealistic expectation to show higher velocity to prove
productivity
Delphi Method
The Delphi Method is an information gathering
technique that was created in the 1950s by the RAND Corporation. The Delphi
Method is based on the surveys and makes use of the information of the
participants, who are mainly experts. Under this method of software, project
specification would be given to a few experts and their opinion taken. The
steps taken to get the estimation using are:
(i) Selection of experts, (ii) Briefing the experts about the project,
objective of the estimation and overall project scope and clarification, (iii)
Collate the estimates (software size and development effort) received from the
experts and finally (iv) Convergence of estimates and finalization
The major advantages of Delphi technique are
that it’s very simple to administer and also can be derived relatively quicker.
Also, it is useful when the organization does not have any in-house experts
with the domain knowledge to come out with a quick estimate. On the contrary,
the disadvantages primarily come from selecting the wrong experts as well as
getting adequate number of experts willing to participate in the estimation.
Moreover, it is not possible to determine the causes of variance between the
estimated value and the actual values.
Heuristic Method
Heuristic methods of estimation are
essentially based on the experience that exists within a particular
organization where past projects are used to estimate the required resources
necessary to deliver future projects. A convenient sub-classification is to
divide heuristic methods into ‘top-down’ and ‘bottom-up’ approaches. These
approaches are the de-facto methods
by which estimates are produced and as such they are implicated in being poor
reflections of the actual resources that are required as evidenced by the
failure of projects to be estimated accurately.
Top-down approaches to effort estimation may rely on the opinion of an
expert whereas the Bottom-up estimation is the process by which time needed to
code each identified module is estimated based on the discrete tasks that must
be performed, such as analysis, design and project management.
Despite its simplistic approach, the error margin
of heuristic
method’s estimation is not proven to be worse than any other parametric or
algorithmic (COCOMO, UUCP, etc.) estimation models. This doesn’t come free of
risk either. The lack of access to historical data will cause high degree of
error margin of future project and the underlying assumption of repeatability
of organizations success could be proved to be deadly. Moreover, if not
conducted systematically, tasks such as integration, quality and configuration
could be overlooked
There is another category that usually people don't talk a lot, which is - home grown estimation models. Those models are created by the team members of a software project where they're working for quite a long period of time and those work pretty good for their projects. As those kind of estimation models typically aren't standardize to use for software projects outside of that group, those are usually not made public. To get a flavor of that kind of models, you can check out the JEE Software Development Estimation post where I have posted such a model which I used in 2008 in one of my software project.
In my next post of this series, I would cover the famous "Cone of Uncertainty" in software project management as well as the influence of human psychology in software estimation. Stay tuned!